By Rocky Roden and ChingWen Chen, Ph.D. | Published with permission: First Break | May 2017
Introduction
In conventional geological settings, oil companies routinely evaluate prospects for their drilling portfolio where the process of interpreting seismic amplitude anomalies as Direct Hydrocarbon Indicators (DHIs) plays an important role. DHIs are an acoustic response owing to the presence of hydrocarbons and can have
a significant impact on prospect risking and determining well locations (Roden et al., 2005; Fahmy 2006; Forrest et al., 2010; Roden et al., 2012; Rudolph and Goulding, 2017). DHI anomalies are caused by changes in rock physics properties (P and S wave velocities, and density) typically of the hydrocarbon-filled
reservoir in relation to the encasing rock or the brine portion of the reservoir. Examples of DHIs include bright spots, flat spots, character/phase change at a projected oil or gas/water contact, amplitude conformance to structure, and an appropriate amplitude variation with offset on gathers. Many uncertainties should be considered and analyzed in the process of assigning a probability of success and resource estimate range before including a seismic amplitude anomaly prospect in an oil company’s prospect portfolio (Roden et al., 2012).
Seismic amplitude anomalies that are DHIs have played a major role in oil and gas exploration since the early 1970s (Hilterman, 2001). The technology and methods to identify and risk seismic amplitude anomalies have advanced considerably over the years, especially with the use of AVO (Amplitude vs. Offset) and improved acquisition and processing seismic technology (Roden et al., 2014). The proper evaluation of seismic direct hydrocarbon indicators for appropriate geologic settings has proven to have a significant impact on risking prospects. Rudolph and Goulding (2017) indicate from an ExxonMobil database of prospects that DHI-based prospects had over twice the success rate of non-DHI prospects on both a geologic and economic basis. In an industry-wide database of DHI prospects from around the world, Roden et al. (2012) indicate that when a prospect has a >20% DHI Index, a measure of the risk associated with DHI characteristics, almost all the wells were successful. Even with the use of advanced seismic technology and well-equipped interpretation workstations, the interpretation of DHI characteristics is not always easy or straightforward.
A key technology employed in evaluating potential DHI features is seismic attributes. Seismic attributes are any measurable property of seismic data including stacked or prestack data. Seismic attributes can be computed on a trace, multiple traces, on an entire volume, over isolated windows, on a horizon, and in either
time or depth. There are hundreds of seismic attributes generated in our industry (Brown, 2004; Chen and Sidney, 1997; Chopra and Marfurt, 2007; Taner, 2003) and can be generally categorized as instantaneous, geometric, AVO, seismic inversion, and spectral decomposition attributes. The instantaneous, AVO, and inversion attributes are typically utilized to highlight and identify DHI features. For example, amplitude envelope, average energy, and sweetness are good instantaneous attributes to display how amplitudes stand out above the background, potentially identifying a bright spot and a potential hydrocarbon accumulation. AVO attributes such as intercept times gradient, fluid factor, Lambda/Mu/Rho and far offset-minus near offset-times the far offset can help to identify hydrocarbon-bearing reservoirs (Roden et al., 2014). However, not all amplitude anomalies are DHIs and interpreting numerous seismic attributes can be complicated and at times confusing. In addition, it is almost impossible for geoscientists to understand how numerous seismic attributes (>3) interrelate.
Over the last few years, machine learning has evolved to help interpreters handle numerous and large volumes of data (e.g. seismic attributes) and help to understand how these different types of data relate to each other. Machine learning uses computer algorithms that iteratively learn from the data and independently adapt to produce reliable, repeatable results. We incorporate a machine learning workflow where principal component analysis (PCA) and self-organizing maps (SOM) are employed to analyze combinations of seismic attributes for meaningful patterns that correspond to direct hydrocarbon indicators. A machine learning multi-attribute approach with the proper input parameters can help interpreters to more efficiently and accurately evaluate DHIs and help reduce risk in prospects and projects.
Interpreting DHIs

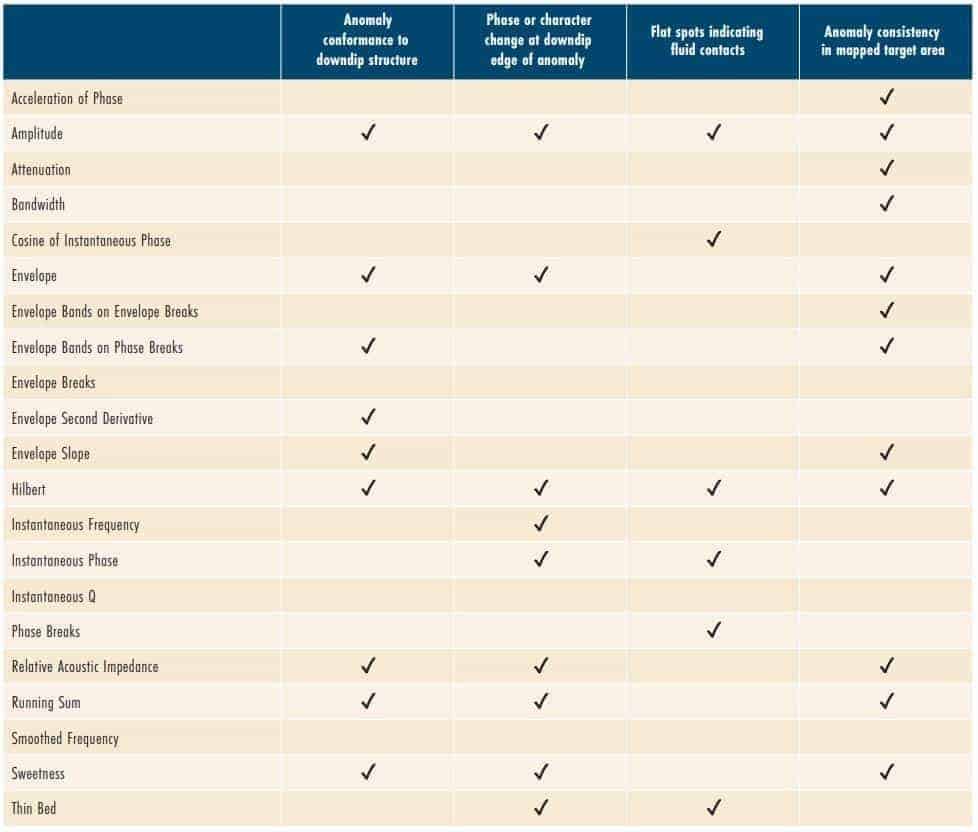
DHI characteristics are usually associated with anomalous seismic responses in a trapping configuration: structural traps, stratigraphic traps, or a combination of both. These include bright spots, flat spots, amplitude conformance to structure, etc. DHI anomalies are also compared to other features such as models, similar events, background trends, proven productive anomalies, and geologic features. DHI indicators can also be located below presumed trapped hydrocarbons where shadow zones or velocity pull-down effects may be present. DHI effects can even be present dispersed in the sediment column in the form of gas chimneys or clouds. Forrest et al. (2010) and Roden et al. (2012) have documented the most important DHI characteristics based on well success rates in an industry-wide database of DHI prospects. Other than the amplitude strength above background (bright spots), Table 1 lists these DHI characteristics by AVO classes 2 and 3. These two AVO classes (Rutherford and Williams, 1989) relate to the amplitude with offset response from the top of gas sands which represent the specific geologic settings where most DHI characteristics are found. Therefore, the application of machine learning employing seismic multi-attribute analysis may help to clearly define DHI characteristics and assist the interpreter in making a more accurate assessment of prospect risk.
Multi-attribute machine learning workflow
With the goal of identifying DHI characteristics, an interpreter must determine the specific attributes to employ in a machine learning workflow. A geoscientist can select appropriate attributes based on their previous knowledge and experience to define DHIs in a specific play or trend. Table 2 lists several common instantaneous attributes and the associated stacked seismic data DHI characteristics they tend to identify. These relationships are of course subjective and depend on the geologic setting and data quality. Class 3 DHIs are usually interpreted on full stack volumes and/or offset/angle volumes and their associated derivative products. Class 2 DHIs are typically interpreted on offset/angle volumes (especially far offset/angle volumes), gathers, and their associated derivative products including various types of crossplots. The relationships between attributes and DHI characteristics can be variable depending on the geologic setting and the seismic data quality. If it is unclear which attributes to employ, principal component analysis (PCA) can assist interpreters. PCA is a linear mathematical technique to reduce a large set of variables (seismic attributes) to a smaller set that still contains most of the variation of independent information in the larger set. In other words, PCA helps to determine the most meaningful seismic attributes.
The first principal component accounts for as much of the variability in the data as possible and each succeeding component (orthogonal to each preceding) accounts for as much of the remaining variability. Given a set of seismic attributes generated from the same original volume, PCA can identify combinations of attributes producing the largest variability in the data suggesting these combinations of attributes that will better identify specific geologic features of interest and in this case specific DHI characteristics. Even though the first principal component represents the largest linear attribute combinations that best represents the variability of the bulk of the data, it may not identify specific features of interest to the interpreter. The interpreter should also evaluate succeeding principal components because they may be associated with DHI characteristics not identified with the first principal component. In fact, the top contributing seismic attributes from the first few principal components, when combined, often produce the best results for DHI delineation. In other words, PCA is a tool that, employed in an interpretation workflow with a geoscientist’s knowledge of DHI related attributes, can give direction to meaningful seismic attributes and improve interpretation results. It is logical, therefore, that a PCA evaluation may provide important information on appropriate seismic attributes to take into a self-organizing map generation.
After appropriate seismic attributes have been selected, the next level of interpretation requires pattern recognition and classification of often subtle information embedded in the seismic attributes. Taking advantage of today’s computing technology, visualization techniques, and understanding of appropriate parameters, self-organizing maps (SOMs) efficiently distill multiple seismic attributes into classification and probability volumes (Smith and Taner, 2010; Roden et al., 2015). Developed by Kohonen in 1982 (Kohonen, 2001), SOM is a powerful non-linear cluster analysis and pattern recognition approach that helps interpreters to identify patterns in their data that can relate to geologic features and DHI characteristics. The samples for each of the selected seismic attributes from the desired window in a 3D survey are placed in attribute space where they are normalized or standardized to the same scale. Also in attribute space are neurons, which are points in space that start at random locations and train from the attribute data and mathematically hunt for natural clusters of information in the seismic data. After the SOM analysis, each neuron will have identified a natural cluster as a pattern in the data. These clusters reveal significant information about the classification structure of natural groups that are difficult to view any other way. In addition to the resultant classification volume, a probability volume is also generated which is a measure of the Euclidean distance from a data point to its associated winning neuron (Roden et al., 2015). The winning neuron is the one that is nearest to the data point in attribute space. It has been discovered that a low classification probability corresponds to areas that are quite anomalous as opposed to high probability zones that relate to regional and common events in the data.
To interpret the SOM classification results, each neuron is displayed in a 2D color map. Highlighting a neuron or combination of neurons in a 2D color map identifies their associated natural clusters or patterns in the survey because each seismic attribute data point retains its physical location in the 3D survey. The identification of these patterns in the data enables interpreters to define geology not easily interpreted from conventional seismic amplitude displays alone. These visual cues are facilitated by an interactive workstation environment.
Low probability anomalies
After the SOM process and natural clusters have been identified, Roden et al. (2015) describe the calculation of a classification probability. This probability estimates the probable certainty that a winning neuron classification is successful. The classification probability ranges from zero to 100% and is based on goodness of fit of the Euclidean distances between the multi-attribute data points and their associated winning neuron. Those areas in the survey where the classification probability is low correspond to areas where no winning neurons fit the data very well. In other words, anomalous regions in the survey are noted by low probability. DHI characteristics are often associated with low classification probabilities because they are anomalous features that are usually not widespread throughout the survey.
SOM analysis for Class 3 DHI characteristics
A class 3 geologic setting is associated with low acoustic impedance reservoirs that are relatively unconsolidated. These reservoirs typically have porosities greater than 25% and velocities less than 2700 m/sec. The following DHI characteristics are identified by multi-attribute SOM analyses in an offshore Gulf of Mexico class 3 setting. This location is associated with a shallow oil and gas field (approximately 1200 m) in a water depth of 140 m that displayed a high seismic amplitude response. Two producing wells with approximately 30 m of pay each were drilled in this field on the upthrown side of an east-west trending normal fault. Before these wells were drilled, operators had drilled seven unsuccessful wells in the area based on prominent seismic amplitudes that were either wet or low saturation gas. Therefore, the goal was to identify as many DHI characteristics as possible to reduce risk and accurately define the field and to develop SOM analysis approaches that can help to identify other possible prospective targets in the area.
Initially, 20 instantaneous seismic attributes were run through a PCA analysis in a zone 20ms above and 150 ms below the top of the mapped producing reservoir. Based on these PCA results, various combinations of attributes were employed in different SOM analyses with neuron counts from 3X3, 5X5, 8X8, 10X10, and 12X12 employed for each set of seismic attributes. It is from this machine learning multi-attribute interpretation workflow that the results defining different DHI characteristics were interpreted and described below. All of the figures associated with this example are from a SOM analysis with a 5X5 neuron count and employed the instantaneous attributes listed below.
- Sweetness
- Envelope
- Instantaneous Frequency
- Thin Bed
- Relative Acoustic Impedance
- Hilbert
- Cosine of Instantaneous Phase
- Final Raw Migration
Figure 1a displays a time structure map as denoted by the contours with an amplitude overlay (color) from the mapped top of the reservoir in this field. The horizon at the top of the reservoir was picked on a trough (low impedance) on zero phase seismic data (SEG normal polarity). Figure 1a indicates that there is a relatively good amplitude conformance to structure based on the amplitude. Figure 1b is a display of classification probability from the SOM analysis at the top of the reservoir at the same scale as Figure 1a. This indicates that the top of this reservoir exhibits an anomalous response from the SOM analysis where any data points with a probability of less than 1% are displayed in the white areas. In comparing Figure 1a and 1b it is apparent that the low probability area corresponds closely to the amplitude conformance to structure as denoted by the yellow outline in Figure 1b. This confirms the identification of the productive area with low probability and proves the efficacy of this SOM approach. The consistency of the low probability SOM response in the field is another positive DHI indicator. In fact, the probabilities as low as .01% still produce a consistent response over the field indicating how the evaluation of low probability anomalies is critical in the interpretation of DHI characteristics.
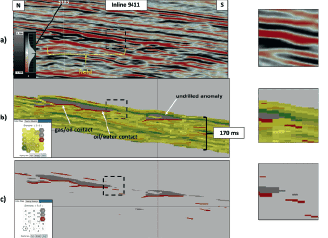
This field contains oil with a gas cap and before drilling, there were hints of possible flat spots suggesting hydrocarbon contacts on the seismic data, but the evidence was inconsistent and not definitive. Figure 2 displays a north-south vertical inline profile through the middle of the field and its location is denoted in Figure 1. Figure 2a exhibits the initial stacked amplitude data with the location of the field annotated. Figure 2b denotes the SOM analysis results of this same vertical inline 9411 which incorporated the eight instantaneous attributes listed above in a 5X5 neuron matrix. The associated 2D color map in Figure 2b denotes the 25 natural patterns or clusters identified from the SOM process. It is apparent in this figure that the reservoir and portions of the gas/oil contact and the oil/water contact are easily identified. This is more easily seen in Figure 2c where the 2D color map indicates that the neurons highlighted in grey (20 and 25) are defining the hydrocarbon-bearing portions of the reservoir above the hydrocarbon contacts and the flat spots interpreted as hydrocarbon contacts are designated by the rust-colored neuron (15). The location of the reservoir and hydrocarbon contacts are corroborated by well control. The southern edge of the reservoir is revealed in the enlargements of the column displays on the right. Downdip of the field is another undrilled anomaly defined by the SOM analysis that exhibits similar DHI characteristics identified by the same neurons.
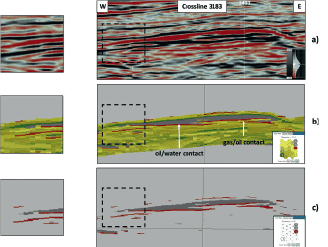
West to east crossline 3179 over the field is displayed in Figure 3 and with it the location designated in Figure 1. The stacked seismic amplitude display of Figure 3a indicates that its tie with inline 9411 is located in the updip portion of the reservoir where there is an apparent gas/oil contact. Figure 3b exhibits the SOM results of this west-east line utilizing 25 neurons as designated by the 2D color map. Similar to Figure 2b, Figure 3b indicates that the SOM analysis has clearly defined the reservoir by the grey neurons (20 and 25) and the hydrocarbon contacts in the rust-colored neuron (15). Towards the west, the rust-colored neuron (15) denotes the oil/water contact as defined by the flat spot on this crossline. Figure 3c displays only neurons 15, 20, and 25 to clearly define the reservoir, its relationship above the hydrocarbon contacts, and the contacts themselves. The three enlargements on the left are added for detail.
What is very evident from the SOM results in both Figures 2 and 3 is a clear character change and definition of the downdip edges of the reservoir. The downdip edge definition of an interpreted trap is an important DHI characteristic that is clearly defined by the SOM analysis in this field. The expanded insets in Figures 2 and 3 indicate that the SOM results are producing higher resolution results than the amplitude data alone and the edge terminations of the field are easily interpreted. These results substantiate that the SOM process with the appropriate set of seismic attributes can exhibit thin beds better than conventional amplitude data.
SOM analysis for Class 2 DHI characteristics
A class 2 geologic setting contains reservoirs more consolidated than class 3 and the acoustic impedance of the reservoirs are about equal to the encasing sediments. Typical porosities range from 15 to 25% and velocities 2700-3600 m/sec for these reservoirs. In class 2 settings, AVO attributes play a larger role in the evaluation of DHI characteristics than in class 3 (Roden et al., 2014). This example is located onshore Texas and targets Eocene sands at approximately 1830 m deep. The initial well B was drilled just downthrown on a small southwest-northeast regional fault, with a subsequent well drilled on the upthrown side (Well A). The reservoirs in the wells are approximately 5-m thick and composed of thinly laminated sands. The tops of these sands produce a class 2 AVO response with near zero amplitude on the near offsets and an increase in negative amplitude with offset (SEG normal polarity).
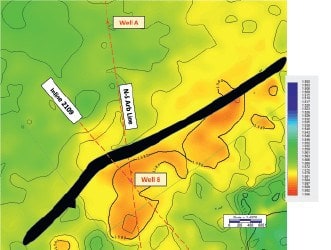
The goal of the multi-attribute analysis was to determine the full extent of the reservoirs revealed by any DHIs because both wells were performing much better than the size of the amplitude anomaly indicated from the stack and far offset seismic data. Figure 4 is a time-structure map from the top of the Eocene reservoir. This map indicates that both wells are located in stratigraphic traps with Well A situated on southeast dip and Well B located on the northwest dip that terminates into the regional fault. The defined anomaly conformance to downdip closure cannot be seen in the Well A reservoir because the areal extent of the reservoir is in a north-south channel and the downdip conformance location is
very narrow. In the Well B reservoir, the downdip edge of the reservoir actually terminates into the fault so an interpretation of the downip conformance cannot be determined. The updip portion of the reservoir at Well B actually thins out towards the south-east forming an updip seal for the stratigraphic trap. The Well B reservoir was interpreted to have a stacked data amplitude anomaly of approximately 70 acres and the Well A reservoir was determined to only have an amplitude anomaly of only about 34 acres (Figure 5a).
The gathers associated with the 3D PSTM survey over this area were conditioned and employed in the generation of very specific AVO attributes conducive to the identification of class 2 AVO anomalies in this geologic setting. The ten AVO attributes used for the SOM analysis were selected from a PCA analysis of 18 AVO attributes. The AVO attributes that were selected for the SOM analysis are listed below:
- Far – Near
- Shuey 2 term approximation – Intercept
- Shuey 2 term approximation – Gradient
- Shuey 2 term approximation – 1/2 (Intercept + Gradient)
- Shuey 2 term approximation – 1/2 (Intercept – Gradient)
- Shuey 3 term approximation – Intercept
- Shuey 3 term approximation – Gradient
- Shuey 3 term approximation – 1/2 (Intercept + Gradient)
- Verm-Hilterman approximation – Normal Incident
- Verm-Hilterman approximation – Poisson’s Reflectivity
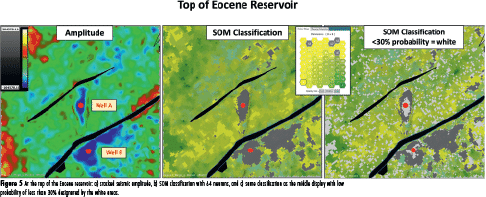
Several different neuron counts were generated with these ten AVO attributes and the results in the associated figures are from the 8X8 (64 neurons) count. Figure 5b displays the SOM results from the top of the Eocene reservoirs. The associated 2D color map indicates that neurons 47, 58, 62, and 63 are defining the reservoirs drilled by the two wells. Comparing the areal distribution of the amplitude defined reservoirs in 5a to the SOM defined reservoirs in Figure 5b indicates that the later is larger. In fact, the Well A amplitude defined area of 34 acres is compared to approximately 95 acres as denoted by four neurons in Figure 5b. The Well B amplitude defined reservoir area was determined to be 70 acres, whereas, the SOM defined area was determined to be approximately 200 acres. The SOM defined areal distributions were determined to be consistent with engineering and pressure data in the two wells. The anomaly consistency in the mapped target area is evident in Figure 5b and is better in defining the extent of the producing reservoirs than amplitudes.
Figure 5c displays the SOM results of 5b. However, less than 30% of the low classification probability results are displayed in white. It denotes that the core of the reservoirs at each of the well locations reveal low probability. Low probability is defining anomalous zones based on the ten AVO attributes run in the SOM classification process.
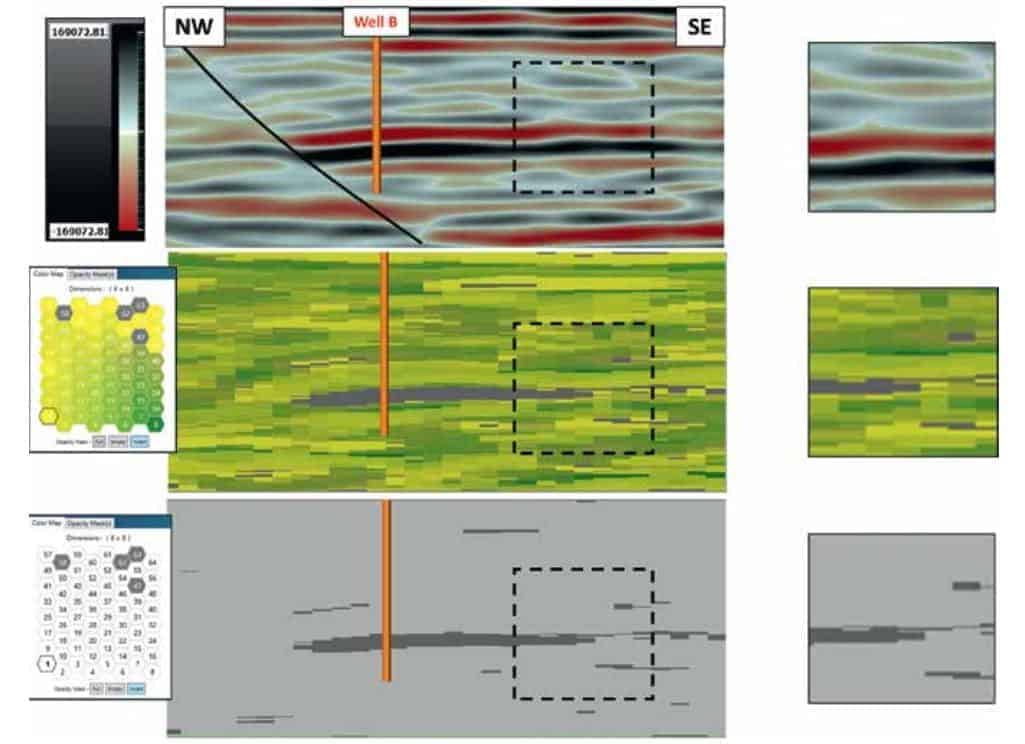
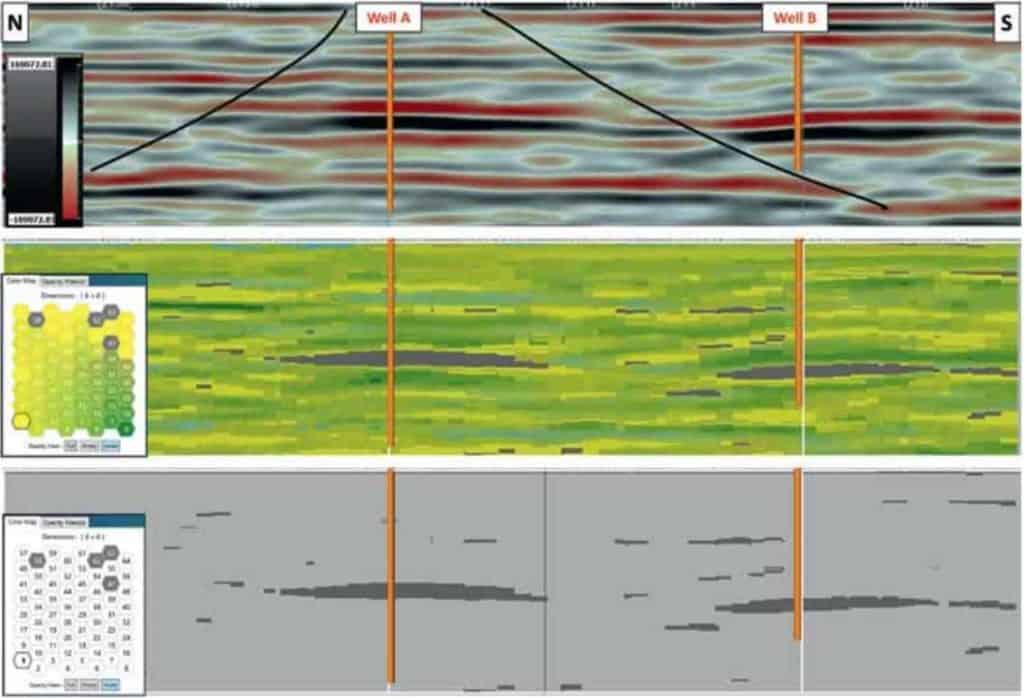
Figure 6 is a north-south arbitrary line running through both Wells A and B with its location denoted in Figure 4. Figure 6a is the conventional stacked seismic amplitude display of this line. Figure 6b displays the SOM results and the reservoirs at both wells defined by neurons 47, 58, 62, and 63. In Figure 6c only these four neurons are turned on defining the location of the reservoirs on this line. The four neurons are clearly defining the field and the southern downdip limits of the reservoir associated with Well A and the updip limits of the reservoir at Well B where the sands are thinning out to the south. Figure 7 is northwest-southeast inline 2109 with its location denoted in Figure 4. Figure 7a is the stacked amplitude display and Figure 7b displays the SOM results defining the limits of the Well B reservoir as it terminates at the fault to the northwest. Figure 7c with only the four neurons defining the reservoir displayed indicates the thinning out of the reservoir updip much more clearly than with amplitudes alone. The insets of Figures 7b and 7c illustrate the details in the updip portion of the reservoir defined by the SOM process. The SOM analysis incorporates ten AVO attributes and is not limited by conventional amplitude/frequency limitations of thickness and areal distribution. The AVO attributes selected for this SOM analysis are specifically designed to bring out the appropriate AVO observations for a class 2 setting. It is clear from these results that the AVO attributes in this SOM analysis are clearly distinguishing the anomalous areas associated with the producing reservoirs from the equivalent events and zones outside these stratigraphic traps.
Conclusions
For more than 40 years seismic amplitudes have been employed to interpret DHIs in an attempt to better define prospects and fields. There are dozens of DHI characteristics associated primarily with class 2 and 3 geologic settings. Hundreds of seismic attributes have been developed in an effort to derive more information from the original seismic amplitude data and further improve DHI interpretations. A machine learning workflow incorporating seismic attributes, PCA, and SOM, has been proven to produce excellent results in the interpretation of DHIs. This machine learning workflow was applied to data in class 2 and 3 reservoirs in an effort to interpret the most important DHI characteristics as defined by a worldwide industry database. The SOM analysis employing instantaneous attributes in a class 3 setting successfully identified the top DHI characteristics and especially those defining edge effects and hydrocarbon contacts (flat spots). AVO attributes conducive to providing information in class 2 settings incorporated in a SOM analysis allowed the interpretation of DHI characteristics that better defined the areal extent of the producing reservoirs than amplitudes by clearly denoting the stratigraphic trap edges.
Low SOM classification probabilities have been proven to help identify DHI characteristics. These low probabilities relate to data regions where the attributes are very different from the data points of all of the attributes in the SOM analysis and their associated winning neurons, which has defined a natural cluster or pattern in the data. Anomalous regions in the data, for example, DHI characteristics, are noted by low probability. This analytical approach of defining low probabilities proved to be helpful in identifying DHI characteristics in both class 2 and 3 settings.
An important observation in these two case studies is that the use of appropriate seismic attributes in a SOM analysis can not only identify DHI characteristics not initially interpreted but can also increase or decrease confidence in already identified characteristics. This multi-attribute machine learning workflow provides a methodology to produce more accurate identification of DHI characteristics and a better risk assessment of a geoscientist’s interpretation.
Acknowledgments
The authors would like to thank the staff of Geophysical Insights for the research and development of the machine learning applications used in this paper. We would also like to thank the Rose & Associates DHI consortium, which has provided extremely valuable information on DHI characteristics. The seismic data in the offshore case study is courtesy of Petroleum Geo-Services. Thanks also go to Deborah Sacrey and Mike Dunn for reviewing the paper. Finally, we would like to thank Tom Smith for reviewing this paper and for the inspiration to push the boundaries of interpretation technology.
References
Brown, A.B, [2004]. Interpretation of three-dimensional seismic data. AAPG Memoir 42/SEG Investigations in Geophysics No. 9, sixth edition.
Chen, Q. and Sidney, S. [1997]. Seismic attribute technology for reservoir forecasting and monitoring. The Leading Edge, 16, 445-448. Chopra, S. and Marfurt, K. [2007]. Seismic attributes for prospect identification and reservoir characterization. SEG Geophysical Development Series No. 11.
Fahmy, W.A. [2006]. DHI/AVO best practices methodology and applications: a historical perspective. SEG/EAGE Distinguished Lecture presentation.
Forrest, M., Roden, R. and Holeywell, R. [2010]. Risking seismic amplitude anomaly prospects based on database trends. The Leading Edge, 5, 936-940.
Hilterman, F.J. [2001]. Seismic amplitude interpretation. Distinguished instructor short course, SEG/EAGE. Kohonen, T. [2001]. Self Organizing Maps. Third extended addition, Springer Series in Information Services, Vol. 30.
Roden, R., Forrest, M. and Holeywell, R. [2005]. The impact of seismic amplitudes on prospect risk analysis. The Leading Edge, 7, 706-711.
Roden, R., Forrest, M. and Holeywell, R. [2012]. Relating seismic interpretation to reserve/resource calculations: Insights from a DHI consortium. The Leading Edge, 9, 1066-1074.
Roden, R., Forrest, M., Holeywell, R., Carr, M. and Alexander, P.A. [2014]. The role of AVO in prospect risk assessment. Interpretation, 2, SC61-SC76.
Roden, R., Smith, T. and Sacrey, D. [2015]. Geologic pattern recognition from seismic attributes: Principal component analysis and self-organizing maps. Interpretation, 3, SAE59-SAE83.
Rudolph, K.W. and Goulding, F.J. [2017]. Benchmarking exploration predictions and performance using 20+ yr of drilling results: One company’s experience. AAPG Bulletin, 101, 161-176.
Rutherford, S.R. and Williams, R.H. [1989]. Amplitude-versus-offset variations in gas sands: Geophysics, 54, 680-688.
Smith, T. and Taner, M.T. [2010]. Natural clusters in multi-attribute seismics found with self-organizing maps. Extended Abstracts, Robinson-Treitel Spring Symposium by GSH/SEG, March 10-11, 2010, Houston, Tx.
Taner, M.T. [2003]. Attributes revisited. http://www.rocksolidimages.com/pdf/attrib_revisited.htm, accessed 13 August 2013.


















