By David Brown, Explorer Correspondent | Published with permission: AAPG Explorer | June 2019
The concept of digital transformation in the oil and gas industry gets talked about a lot these days, even though the phrase seems to have little specific meaning.
So, will there really be some kind of extensive cyber-transformation of the industry over the next decade?
“No,” said Tom Smith, president and CEO of Geophysical Insights in Houston.
Instead, it will happen “over the next three years,” he predicted.
Machine Learning
Much of the industry’s transformation will come from advances in machine learning, as well as continuing developments in computing and data analysis going on outside of oil and gas, Smith said.
Through machine learning, computers can develop, modify and apply algorithms and statistical models to perform tasks without explicit instructions.
“There’s basically been two types of machine learning. There’s ‘machine learning’ where you are training the machine to learn and adapt. After that’s done, you can take that little nugget (of adapted programming) and use it on other data. That’s supervised machine learning,” Smith explained.
“What makes machine learning so profoundly different is this concept that the program itself will be modified by the data. That’s profound,” he said.
Smith earned his master’s degree in geology from Iowa State University, then joined Chevron Geophysical as a processing geophysicist. He later left to complete his doctoral studies in 3-D modeling and migration at the University of Houston.
In 1984, he founded the company Seismic Micro-Technology, which led to development of the KINGDOM software suite for integrated geoscience interpretation. Smith launched Geophysical Insights in 2009 and introduced the Paradise analysis software, which uses machine learning and pattern recognition to extract information from seismic data.
He’s been named a distinguished alumnus of both Iowa State and the University of Houston College of Natural Sciences and Mathematics, and received the Society of Exploration Geophysicists Enterprise Award in 2000.
Smith sees two primary objectives for machine learning: replacing repetitive tasks with machines – essentially, doing things faster – and discovery, or identifying something new.
“Doing things faster, that’s the low-hanging fruit. We see that happening now,” Smith said.
Machine learning is “very susceptible to nuances of the data that may not be apparent to you and I. That’s part of the ‘discovery’ aspect of it,” he noted. “It isn’t replacing anybody, but it’s the whole process of the data changing the program.”
Most machine learning now uses supervised learning, which employs an algorithm and a training dataset to “teach” improvement. Through repeated processing, prediction and correction, the machine learns to achieve correct outcomes.
“Another aspect is that the first, fundamental application of supervised machine learning is in classification,” Smith said,
But, “in the geosciences, we’re not looking for more of the same thing. We’re looking for anomalies,” he observed.
Multidimensional Analysis
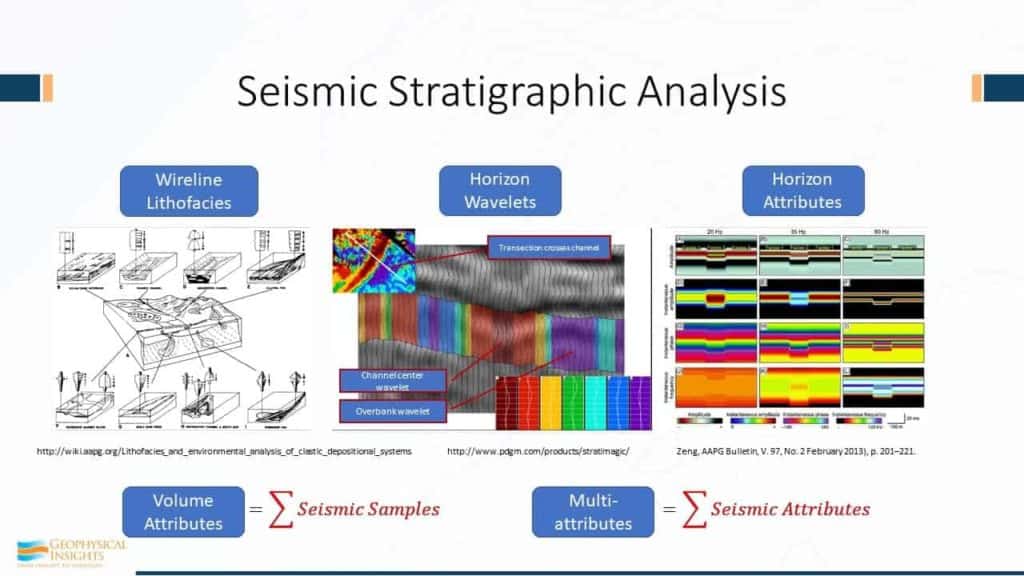
The next step in machine learning is unsupervised learning. Its primary goal Is to learn more about datasets by modeling the structure or distribution of the data – “to self-discover the characteristics of the data,” Smith said.
“If there are concentrations of information in the data, the unsupervised machine learning will gravitate toward those concentrations,” he explained.
As a result of changes in geology and stratigraphy, patterns are created in the amplitude and attributes generated from the seismic response. Those patterns correspond to subsurface conditions and can be understood using machine-learning and deep-learning techniques, Smith said.
Human seismic interpreters can see only in three dimensions, he noted, but the patterns resulting from multiple seismic attributes are multidimensional. He used the term “attribute space” to distinguish from three-dimensional seismic volumes.
In geophysics, unsupervised machine learning was first used to analyze multiple seismic attributes to classify these patterns, a result of concentrations of neurons.
“We see the effectiveness of (using multiple) attributes to resolve thin beds in unconventional plays and to expose direct hydrocarbon Indicators in conventional settings. Existing computing hardware and software now routinely handle multiple-attribute analysis, with 5 to 10 being typical numbers,” he said.
Machine-learning and deep-learning technology, such as the use of convolutional neural networks (CNN), has important practical applications in oil and gas, Smith noted. For instance, the “subtleties of shale-sand fan sequences are highly suited” to analysis by machine learning-enhanced neural networks, he said.
“Seismic facies classification and fault detection are just two of the important applications of CNN technology that we are putting into our Paradise machine-learning workbench this year,” he said.
A New Commodity
Just as a seismic shoot or a seismic imaging program have monetary value, algorithms enhanced by machine-learning systems also are valuable for the industry, explained Smith.
In the future, “people will be able to buy, sell and exchange machine-learning changes in algorithms. There will be industry standards for exchanging these ‘machine-learning engines,’ if you will,” he said.
As information technology continues to advance, those developments will affect computing and data analysis in oil and gas. Smith said he’s been pleased to see the industry “embracing the cloud” as a shared computing-and-data-storage space.
“An important aspect of this is, the way our industry does business and the way the world does business are very different,” Smith noted.
“When you look at any analysis of Web data, you are looking at many, many terabytes of information that’s constantly changing,” he said.
In a way, the oil and gas industry went to school on very large sets of seismic data when huge datasets were not all that common. Now the industry has some catching up to do with today’s dynamic data-and-processing approach.
For an industry accustomed to thinking in terms of static, captured datasets and proprietary algorithms, that kind of mind-shift could be a challenge.
“There are two things we’re going to have to give up. The first thing is giving up the concept of being able to ‘freeze’ all the input data,” Smith noted.
“The second thing we have to give up is, there’s been quite a shift to using public algorithms. They’re cheap, but they are constantly changing,” he said.
Moving the Industry Forward
Smith will serve as moderator of the opening plenary session, “Business Breakthroughs with Digital Transformation Crossing Disciplines,” at the upcoming Energy in Data conference in Austin, Texas.
Presentations at the Energy in Data conference will provide information and insights for geologists, geophysicists and petroleum engineers, but its real importance will be in moving the industry forward toward an integrated digital transformation, Smith said.
“We have to focus on the aspects of machine-learning impact not just on these three, major disciplines, but on the broader perspective,” Smith explained. “The real value of this event, in my mind, has to be the integration, the symbiosis of these disciplines.”
While the conference should appeal to everyone from a company’s chief information officer on down, recent graduates will probably find the concepts most accessible, Smith said.
“Early-career professionals will get it. Mid-managers will find it valuable if they dig a little deeper into things,” he said.
And whether it’s a transformation or simply part of a larger transition, the coming change in computing and data in oil and gas will be one of many steps forward, Smith said.
“Three years from now we’re going to say, ‘Gosh, we were in the Dark Ages three years ago,’” he said. “And it’s not going to be over.”


















