![]()
Stay engaged with the Paradise community through our Blogs

How the Oil and Gas Business has Influenced Computational Advancements
Originally published in Oilman Magazine We owe the oil and gas industry credit for a large part of our understanding of what lies beneath the ground, revealed particularly through seismic ...

Key Findings from Challenges
Hearing about the industry's challenges this year has almost become trite, but those concerns are valid and persist, even as Brent crude is about $48 today (18 Dec. 2020). And ...

Vertical Seismic Profiling Part VII – The Historic 1979 VSP Conference at Phillips
I recently wrote a series of reminisces, each published on this Geophysical Insights home page, about the introduction of VSP practice into the U.S. I wrote all of these stories ...

Vertical Seismic Profiling Part VI – Parting with Evsey and Going My Own Way in the VSP World
Dr. Bob Hardage shares a memory from 1979 SEG Annual Meeting in New Orleans and then summarize factors that pushed him deeply into developing VSP technology ...

Vertical Seismic Profiling Part V – Gal’perin Humor and Joy of Life
Dr. Bob Hardage talks about Gal’perin's sense of humor, his joy of life, and his first experience with a trampoline ...

Vertical Seismic Profiling Part IV – Transferring Gal’perin Principles into the U.S.
Dr. Bob Hardage compares the differences between his work at Phillips and that of Dr. Evsey Gal’perin in the Soviet Union ...

Vertical Seismic Profiling Part III – Russian/English Translators
Dr. Bob Hardage offered to pen a short history of Vertical Seismic Processing (VSP), and its re-emergence in the 1970s at the intersection of geophysics and cold-war era geopolitics between ...

Vertical Seismic Profiling Part II- How the 1979 Linkage Between Hardage and Gal’perin Occurred
Dr. Bob Hardage shared a remarkable story that highlighted the introduction of Vertical Seismic Profiling (VSP) in the U.S. and what was then the Soviet Union. Bob is injecting new ...
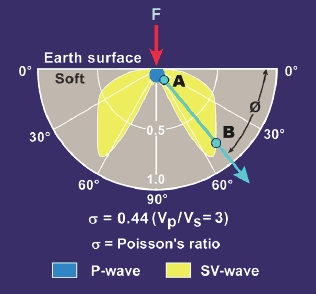
Vertical Seismic Profiling – history, science and geopolitics by Dr. Bob Hardage
Dr. Bob Hardage, one of our colleagues, recently shared a remarkable story that highlights the history of Vertical Seismic Profiling (VSP). Bob has been both a researcher and proponent of ...

Is There a Crisis in Geophysical and Petrophysical Analysis?
Hal Green sharing an evocative question posed by Keith R. Holdaway and Duncan H. B. Irving in their book “Enhance Oil and Gas Exploration with Data-Driven Geophysical and Petrophysical Models” ...


















